About



Easily configure and deploy a fully self-hosted chatbot web service based on open source Large Language Models (LLMs), such as Mixtral or Llama 2, without the need for knowledge in machine learning.
- 🌐 Free and Open Source chatbot web service with UI and API
- 🏡 Fully self-hosted, not tied to any service, and offline capable. Forget about API keys! Models and embeddings can be pre-downloaded, and the training and inference processes can run off-line if necessary.
- 🚀 Easy to setup, no need to program, just configure the service with a YAML file, and start it with 1 command
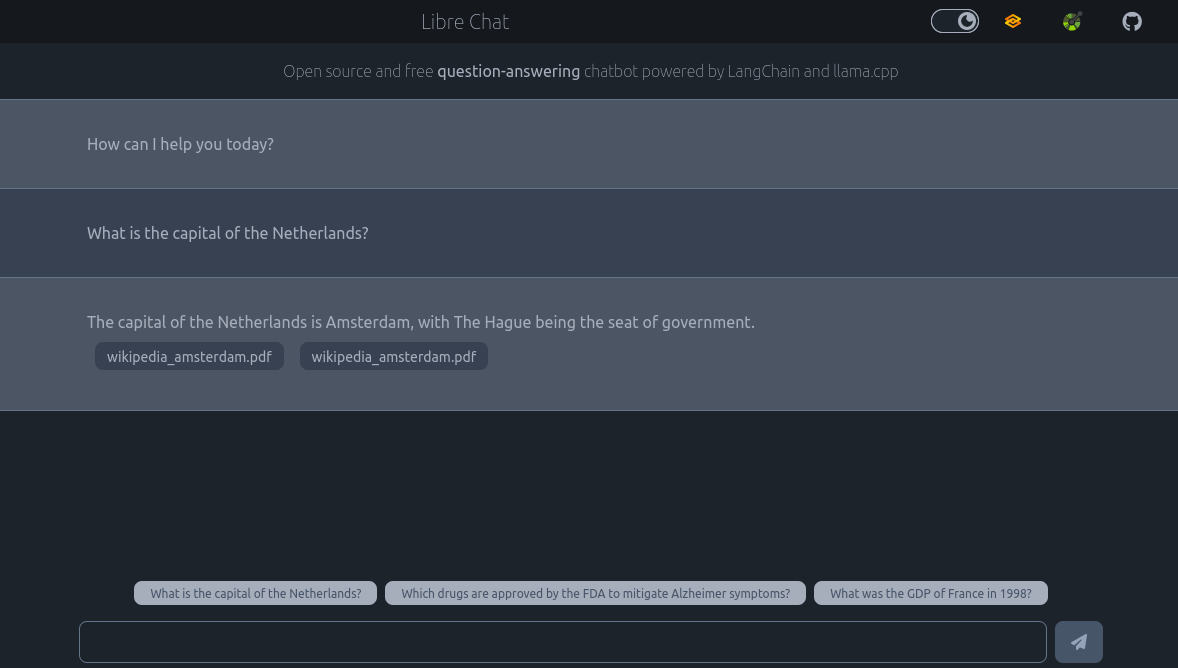
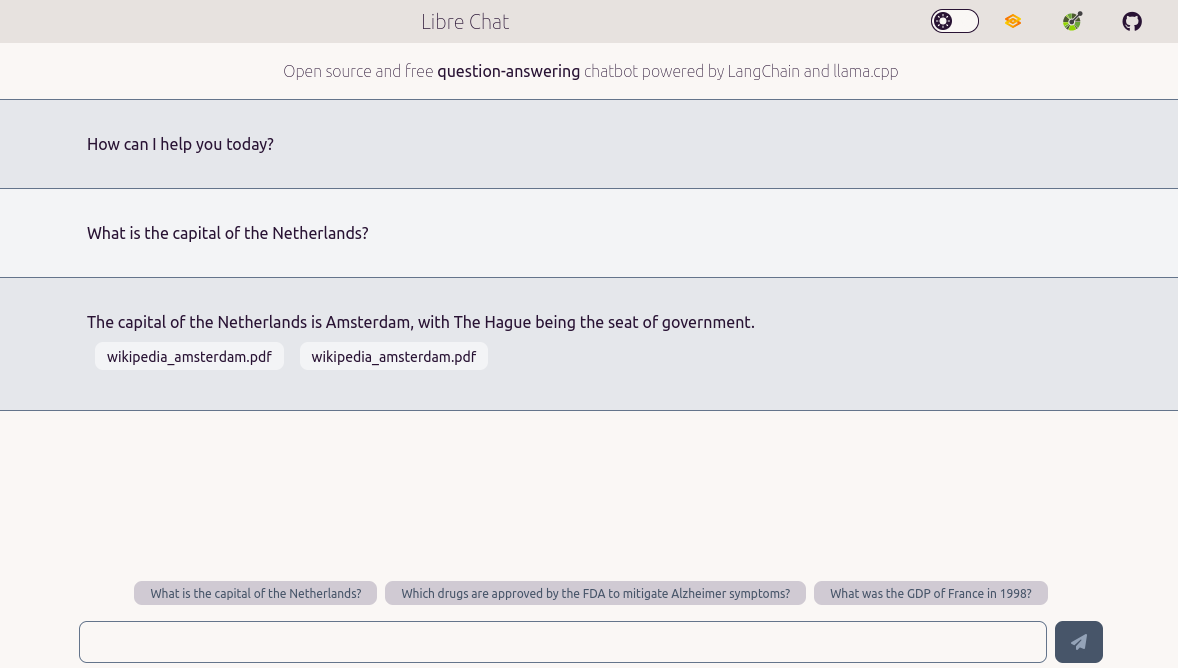
- 🪶 Chat web interface (Gradio-based, or custom HTML), working well on desktop and mobile, with streaming response, and markdown rendering.
- 📦 Available as a
pippackage 🐍, ordockerimage 🐳 - 🐌 No need for GPU, this will work even on your laptop CPU! That said, just running on CPUs can be quite slow (up to 1min to answer a documents-base question on recent laptops).
- 🦜 Powered by
LangChainandllama.cppto perform inference locally. - 🤖 Various types of agents can be deployed:
- 💬 Generic conversation: do not need any additional training, just configure settings such as the template prompt
- 📚 Documents-based question answering (experimental): automatically build similarity vectors from documents uploaded through the API UI, the chatbot will use them to answer your question, and return which documents were used to generate the answer (PDF, CSV, HTML, JSON, markdown, and more supported).
- 🔍 Readable logs to understand what is going on.
Early stage
Development on this project has just started, use it with caution. If you are looking for more mature projects check out the bottom of this page.
ℹ️ How it works
No need to program! The whole deployment can be configured from a YAML file: paths to the model/documents/vectorstore, model settings, web services infos, etc. Create a chat.yml file with your configuration then starts the web service.
-
Install it as a
pippackage 🐍, or create adocker-compose.ymlfile to use thedockerimage 🐳 -
Configure the service in a
chat.ymlfile -
Start the chat web service from the terminal with
libre-chat startordocker compose up
Seasoned developers can also manipulate LLM models, and deploy the API in python scripts using the libre_chat module.
Report issues
Feel free to create issues on GitHub, if you are facing problems, have a question, or would like to see a feature implemented. Pull requests are welcome!
📥 Download supported models
All models supported in GGUF format by llama.cpp should work. Preferably search for the Instruct version of a model (fine-tuned to better follow instructions), e.g.:
Supporting other models
Let us know if you managed to run other models with Libre Chat, or if you would like to see a specific model supported.
🔎 Technical overview
The web service is deployed using a ⚡ FastAPI endpoint. It has 4 routes, plus its OpenAPI documentation available on /docs:
- 📮
GETandPOSTon/promptto query the model - 🔌 Websocket on
/chatto open a connection with the API, and query the model - 🖥️ Chatbot web UI served on the root URL
/
All files required for querying the model are stored and accessed locally using 🦜🔗 LangChain: the main model binary, the embeddings and documents to create the vectors, and the vectorstore.
🗺️ More mature projects
If you are looking for more mature tools to play with LLMs locally we recommend to look into those really good projects:
- chat-langchain: chat UI for LangChain
- ollama: Get up and running with Llama 2 and other large language models locally
- GPT4All: open-source LLM chatbots that you can run anywhere
- llm: Python library for interacting with Large Language Models, both via remote APIs and models that can be installed and run on your own machine, by Simon Willison (checkout their blog simonwillison.net, for a lot of really well written articles about LLMs)
- vLLM: A high-throughput and memory-efficient inference and serving engine for LLMs (includes OpenAI-compatible server, requires GPU)
- ChatDocs: UI to Chat with your documents offline, by the developer of ctransformers
- localGPT: Chat with your documents on your local device using GPT models
- text-generation-webui: A Gradio web UI for Large Language Models